Glassdoor Webscraper: FANG Data Science Interview Questions
Project Overview
Compile Glassdoor Interview Questions and Data for FANG Data Science positions
Project Result
Libraries Used:
- pandas
- BeautifulSoup
- numpy
- urlopen
- requests
- collections
Steps taken:
- Webscrape Glassdoor Data
- Get top 10 most frequent relevant words from interviews
- Clean and format data
- Consolidate into Tableau Dashboard
Step 1. Webscrape Glassdoor Data
First got to the glassdoor and inspect the html code to find out where the data we care about is located.
example link: https://www.glassdoor.com/Interview/Facebook-Data-Scientist-Interview-Questions-EI_IE40772.0,8_KO9,23.htm
The interview question, experience, and offer data are located in classes rather than tables.
import requests
from urllib.request import urlopen
from bs4 import BeautifulSoup
import numpy
import pandas as pd
#Create lists to scrape data into
fb_interview_questions_list = []
fb_interview_experience_list = []
fb_offer_exp_diff_list = []
url = https://www.glassdoor.com/Interview/Facebook-Data-Scientist-Interview-Questions-EI_IE40772.0,8_KO9,23.htm
headers= {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers = headers)
#Make sure web page exists (status code = 200)
if response.status_code != 200:
print('No Glassdoor data for this job title/company combination available')
soup = BeautifulSoup(response.content, 'html.parser')
#Get interview Questions
for span in soup.find_all('span', {'class':'interviewQuestion'}):
fb_interview_questions_list.append(span.text)
#Get interview summaries
for i in soup.find_all(class_ = 'interviewDetails continueReading interviewContent mb-xsm'):
fb_interview_experience_list.append(i.text)
#Offer/No Offer, Positive/Negative Exp, Easy/Avg/Difficult Interview
for span in soup.find_all('span', {'class':'middle'}):
fb_offer_exp_diff_list.append(span.text)
This is for just page 1 on Glassdoor. There are usually more, and for big companies typically hundreds. We can loop through by taking the difference between page 1 and page 2 urls, which is the “_IP2” after the 23 (illustrated below) and creating it as a variable where the number 2 increments until all pages are looped through.
Page 1:
- https://www.glassdoor.com/Interview/Facebook-Data-Scientist-Interview-Questions-EI_IE40772.0,8_KO9,23.htm
Page 2:
- https://www.glassdoor.com/Interview/Facebook-Data-Scientist-Interview-Questions-EI_IE40772.0,8_KO9,23 - _IP2 - .htm
Another issue is that the glassdoor urls will continue to be valid (status_code = 200) no matter how high the number following _IP is. So if there are only 4 pages, the url with _IP5 or greater will still be a valid webpage with the data from the last _IP page (in our example 4). This means we can’t stop our loop using status_code = 200 because that will never happen.
Instead, I added a conidition where I stored data pulled from the previous page and said that if it equals the data pulled from the current page, stop the loop.
page_ctr = 2
while response.status_code == 200 :
#New URL with _IP# variable
url2 = 'https://www.glassdoor.com/Interview/Facebook-Data-Scientist-Interview-Questions-EI_IE40772.0,8_KO9,23.htm'[:-4]+'_IP'+str(page_ctr)+'.htm'
headers= {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url2, headers = headers)
#storing html from previous pull before getting new data
prior_soup = soup
#New html
soup = BeautifulSoup(response.content, 'html.parser')
#If interview questions, experiences, and offer data is the same from previous page then stop
if prior_soup.find_all(class_ = 'interviewDetails continueReading interviewContent mb-xsm') == soup.find_all(class_ = 'interviewDetails continueReading interviewContent mb-xsm') and prior_soup.find_all('span', {'class':'interviewQuestion'}) == soup.find_all('span', {'class':'interviewQuestion'}) and prior_soup.find_all('span', {'class':'middle'}) == soup.find_all('span', {'class':'middle'}):
response.status_code = 404
else:
#Get interview Questions
for span in soup.find_all('span', {'class':'interviewQuestion'}):
fb_interview_questions_list.append(span.text)
#Get interview summaries
for i in soup.find_all(class_ = 'interviewDetails continueReading interviewContent mb-xsm'):
fb_interview_experience_list.append(i.text)
#Offer/No Offer, Positive/Negative Exp, Easy/Avg/Difficult Interview
for span in soup.find_all('span', {'class':'middle'}):
fb_offer_exp_diff_list.append(span.text)
page_ctr += 1
This next part stores offer data, and returns general data from scrape
print("Interview Questions:",len(fb_interview_questions_list))
print("Interview Experiences:",len(fb_interview_experience_list))
#Variables to store offer data
fb_no_offer = 0
fb_accepted_offer = 0
fb_declined_offer = 0
for i in fb_offer_exp_diff_list:
if i == 'No Offer':
fb_no_offer+=1
elif i == 'Accepted Offer':
fb_accepted_offer+=1
elif i == 'Declined Offer':
fb_declined_offer+=1
print("No Offer:", fb_no_offer)
print("Accepted Offer:", fb_accepted_offer)
print("Declined Offer:", fb_declined_offer)
if fb_no_offer + fb_accepted_offer + fb_declined_offer == 0:
pass
else:
print("Pcnt Offers Recieved:", round((fb_accepted_offer + fb_declined_offer) / (fb_accepted_offer + fb_declined_offer + fb_no_offer) * 100,2),'%')
Step 2. Get top 10 most frequent relevant words from interviews
Currently, our fb_interview_questions_list is a list with each instance being the interview questions reported in Glassdoor. We need to convert our fb_interview_questions_list into a list with each instance in the list being a single word from the interviews. For example:
- “How long have you been alive?”
Transform to:
- “How”
- “long”
- “have”
- “you”
- “been”
- “alive?”
There are two functions we can use to do this, join and split.
from collections import Counter
# initialize an empty string
n_str1 = ''
#this takes all instances in a list and joins them into 1 element
n_str1 = n_str1.join(fb_interview_questions_list)
#Split function splits each word into a new instance
n_split_it = n_str1.split()
From here, I made a list of unhelpful words that may appear frequently in the interviews (e.g. ‘The’, ‘I’,’YOU’) and looped through and appended the ones that were NOT in the unhelpful words list into a new list. I made both lists all caps in order to avoid punctuation differences.
unnecessary_words_list = ['ANSWER','ANSWERS','QUESTION','THE','AND','YOU','THAT','QUESTIONS','FOR', 'ON','NOT','LIKE',
'HOW','WITH','ARE','THAT','WAS','HOW','FROM','ASKED','FIND','THEY', 'WE','AN','WERE','AT',
'ABOUT','WOULD','IT','WHAT','MY','WHEN','I','A','OF','TO','IS','DO','YOU','-','THIS','USER',
'A','DO','I','IN','1','2','WHAT','OR','but','be','THE','YOU','WHY','BY','AS','3','IF','ONE', 'HAVE','QUESTIONS.','HAS','4','5','BUT','BE','SOME','NEW','YOUR','THERE','EACH','TWO','NUMBER',
'USING','TIME','ME','HAD','DID','WHICH','BLAH','WHERE']
n_new_list = []
ctr = 0
for a in n_split_it:
if a.upper() in unnecessary_words_list:
pass
else:
fb_new_list.append(a.upper())
Then use the Counter which we imported from collections to give us the top 10 words ranked by frequency.
fb_common_words = Counter(n_new_list)
print(fb_common_words.most_common(10))
Step 3. Clean and format data
In order to effectively analyze and condense all this data into 1 place in Tableau, I needed the data to be in the following format:
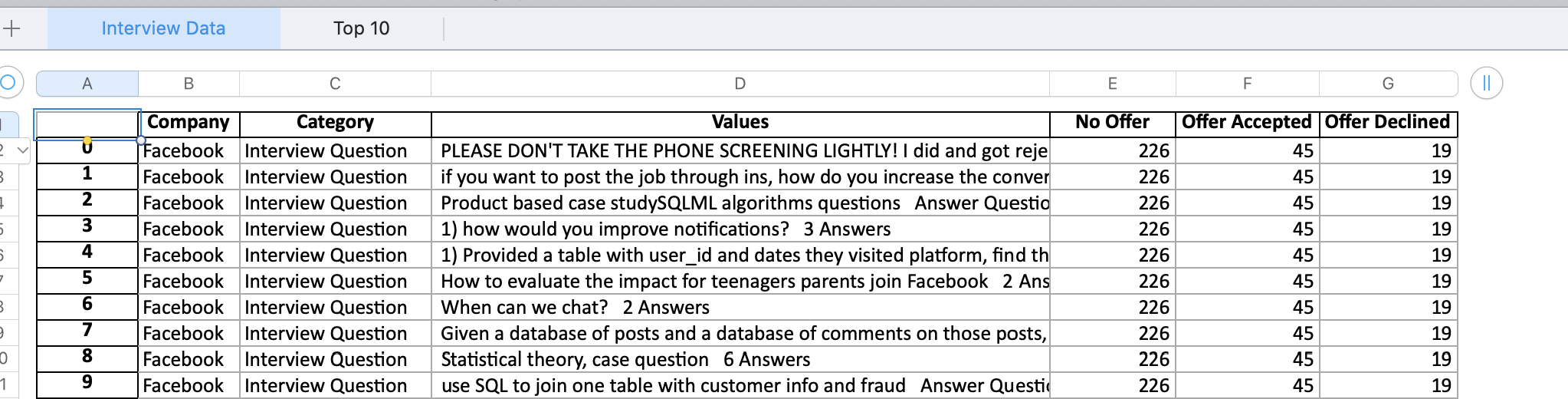
#Creating Category Column List and append Interview Questions or Experience category value to it
fb_category = []
for i in fb_interview_questions_list:
fb_category.append('Interview Question')
for i in fb_interview_experience_list:
fb_category.append('Interview Experience')
#Combine both Interview Questions and Exp actual values
fb_all_lists = fb_interview_questions_list + fb_interview_experience_list
#Create Dataframe and columns using lists and values above
df_fb = pd.DataFrame()
df_fb['Company'] = 'Facebook'
df_fb['Category'] = fb_category
df_n['Values'] = fb_all_lists
df_n['Company'] = 'Facebook'
df_n['No Offer'] = fb_no_offer
df_n['Offer Accepted'] = fb_accepted_offer
df_n['Offer Declined'] = fb_declined_offer
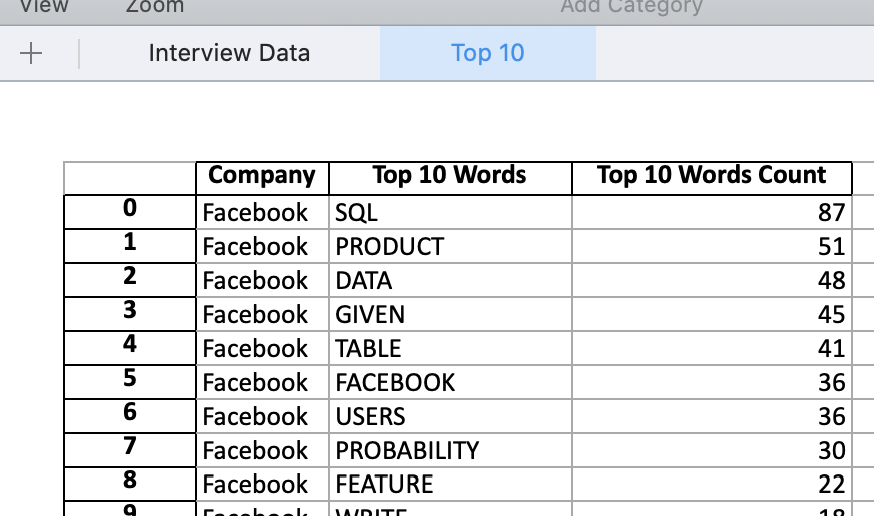
This gets us the dataframe for the first image. The second image dataframe can be obta
#Facebook
#Creating 2 lists: 1 for our top 10 words and the other for their counts
fb_top_ten_words_list = []
fb_top_ten_words_count_list = []
for i in fb_common_words.most_common(10):
fb_top_ten_words_list.append(i[0])
fb_top_ten_words_count_list.append(i[1])
#Create the Dataframe
df_top_10fb = pd.DataFrame()
df_top_10fb['Company'] = 'Facebook'
df_top_10fb['Top 10 Words'] = fb_top_ten_words_list
df_top_10fb['Top 10 Words Count'] = fb_top_ten_words_count_list
df_top_10fb['Company'] = 'Facebook'
In Tableau, we can join these two sheets together when doing our analysis.
Code to save dataframes to seperate sheets:
path = r"Downloads\Python\data\glassdoor.xlsx"
writer = pd.ExcelWriter(path)
df_all.to_excel(writer, sheet_name = 'Interview Data')
df_top_10.to_excel(writer, sheet_name = 'Top 10')
writer.save()
writer.close()
4. Consolidate into Tableau Dashboard
Put it together in Tableau. The questions are stored in lightboxes, which can be used to avoid scrollbars and store large volumes of data without cluttering the visualization.